
TheSkyBlessing数据包解析其二
前言
OhMyDat 是依附于 TSB 项目的一个用于处理实体私有数据的轮子,其通过一个复杂度为O(1)的算法为每一个执行实体分配一个独立的可自由读写的数据空间。在地图中其起到的重要作用包括:
- 备份实体数据,同时根据一个时间戳标识某一个游戏刻的数据时间,避免高频使用
data命令读取实体数据 - 使用类似于编程对象的概念存储一些自定义的实体数据,如游戏内定义的buff和如实体的攻击力抗性等面板数据
在正式开始本篇之前先进行快速吟唱,TSB 是一个可玩性和技术性含量都很高的地图作品,感兴趣的读者推荐自行游玩,涉及第三方作品所以不会完整附上源数据包,这些内容和地图制作团队提供的数据包教程在 TSB 的仓库都可以找到。
数据包介绍
如何理解私有数据存储?在支持面对对象的编程语言中,每一个实例对象所拥有的数据都是独立的,这样的每一个实例对象虽然有着相同的数据格式,但彼此的数据是单独存储在实例身上的。
在MC数据包中,有类似的特性有
- 记分板的计分项。可以实现“实体 - 分数”的映射关系,分数可以看作是实体的私有数据,但是格式必须是整型,无法存储复杂结构。
- 实体的NBT数据,支持复杂结构和
data命令操作,但是高频读写会显著消耗性能。
于是有了OhMyDat的解决方案,其功能用一句话描述为——构建 “实体 - 命令存储” 的唯一映射关系,从而为每个实体分配专属的、独立的命令存储空间。作为轮子数据包(或者叫做工具数据包),其暴露在外的用法是非常简单的,在上一篇解析中已经简单介绍过,这里再重新提一下:
# 使用前执行please函数(函数的执行者必须是要存储数据的实体)
function #oh_my_dat:please
# 获取数据存储
data get storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][-4].DataName
# 修改数据存储
data modify storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][-4].DataName set value DataValue
# 删除数据存储
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][-4].DataName主要的结构可以概括为三个部分
OhMyDayID记分板- 在系统中,每一个实体都有一个独立的 ID 用于查找其数据空间,这个记分板上的分数即是实体被分配的数据空间 ID
- 一个命令存储中的 id 数组
- 也可以称为 ID 队列,ID 记分板中的 id 也会存一份在这个数组中,用于新 id 的分配,新分配的 ID 会被加到数组末尾。需要注意的是记分板和这个数组中的数据并不一定是同步的
- 一个命令存储中的八维数组
- 实体数据空间存储的位置,所有已经分配了 ID 的实体在这个多维数组中都有一个自己的数据空间,通过实体 ID 计算即可得到这个数据空间的索引号
主要函数则包括以下几个
please.mcfunction- 为函数执行者分配 ID 并获取数据空间,或者根据 ID 获取已有数据空间
allocate.mcfunction- 为没有 ID 的实体分配 ID
gc.mcfunction- 在分配 ID 时对系统中无效 ID 和对应数据空间进行清理
provide.mcfunction- 在传入实体 ID 之后,根据 ID 查找对应数据空间
整个系统的几个模块工作流程如下所示,下面也会围绕 ID 分配、ID 清理、ID 查找数据空间三部分模块进行介绍。
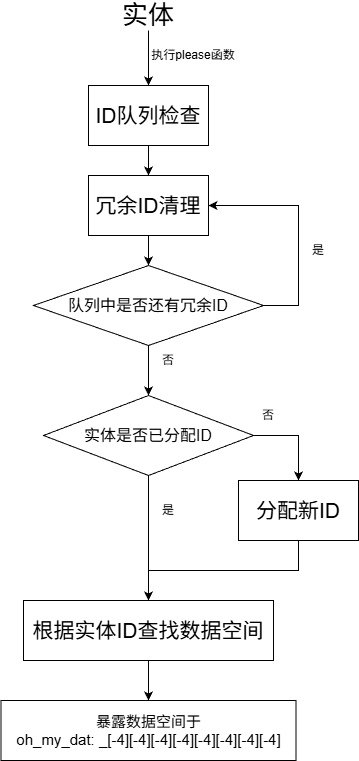
分配新 ID
刚开始进入游戏时,id 记分板为空,id 数组中只有一个 0。为玩家执行please函数时,由于玩家在 id 记分板上没有 id,所以需要先为玩家分配 id,以 id 数组中已有的 id 作为标准,分配 id 的流程如下
- 将数组第一位移到末尾
- 根据(数组第一位 + 数组最后一位)/ 2 的公式得到新的 id
- 新 id 加到数组末尾
- 同步 id 到玩家的记分板分数中
在已分配的 id 足够多的情况下,按照上面的公式 id 会越分越小,但由于新 id 是根据已有 id 计算得到的所以所有 id 都不会重复,而当数组末尾为0时,此时这一位会被替换为可分配 ID 的最大值65536使得新 id 变大,保证不会超过最大值65536。结合刚进入到游戏里的实例来进一步理解这个过程
- 刚进入游戏,数据包初始化。id 数组为[0]
- 以玩家为执行者执行
please函数,得到第一位0和最后一位0,最后一位为0于是被替换为65536 - 计算得到玩家的 id 为
- 更新到玩家的 id 计分项和加到 id 数组中,此时 id 数组为
[0, 32768] - 同步 id 到玩家的记分板分数中
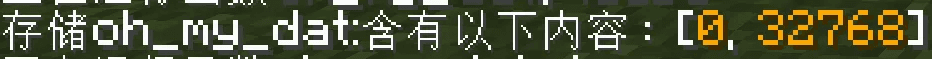
上面由于数组只有一个元素所以无需移位,此时继续为另一个实体执行please函数
- 先把第一位 0 被移到末尾,得到第一位
32768和最后一位0,0被替换为65536 - 计算得到实体的 id 为
- 更新到实体的 id 计分项和加到 id 数组中,此时 id 数组为
[32768, 0, 49152] - 同步 id 到实体的记分板分数中

再为另一个实体执行please函数,重复上面的流程

再执行一次
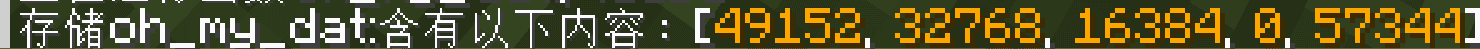
上面已经很形象地演示了系统是如何为生物分配 ID 的,负责分配 ID 的只有一个allocate函数,其内容也十分简单,队列轮转部分则是在gc函数,也就是回收无效 id 那部分中完成的。
——————allocate.mcfunction——————
function oh_my_dat:sys/gc
# 获取id数组的第一位和最后一位,作为新id的参考值
execute store result score $ OhMyDatID run data get storage oh_my_dat: id[-1]
execute store result score $ OhMyDat run data get storage oh_my_dat: id[0]
# 如果最后一位是0则改为65536
execute if score $ OhMyDatID matches 0 run scoreboard players set $ OhMyDatID 65536
# 新id为数组第一位和最后一位之和除以2
scoreboard players operation $ OhMyDatID += $ OhMyDat
scoreboard players set $ OhMyDat 2
scoreboard players operation $ OhMyDatID /= $ OhMyDat
# 将新id同步到id数组和执行者的计分项中
data modify storage oh_my_dat: id append value -1
execute store result storage oh_my_dat: id[-1] int 1 run scoreboard players get $ OhMyDatID
scoreboard players operation @s OhMyDatID = $ OhMyDatIDid同时会被加到数组和实体的记分板分数中,但是前面也提到了两者的分数并不是同步的,实体的记分板分数会在实体清除之后移除,但是 id 数组是在命令存储当中的,此时 id 数组便产生了一个冗余 id,如果实体的数据空间中有数据,这些数据也便成了无用数据。为此我们引入了下面回收 ID 的模块功能
回收无效 id
回收无效 ID 的函数在每次准备为新实体分配 ID 之前都会执行,为了方便理解其功能,这里单独执行这个函数来进行演示。
现在已经为三个实体分配了三个 ID:32768、16384和49152,这些 ID 同时记录在玩家 ID 记分板上,并加入到 ID 队列中。
现在杀死了 ID 为 16384的实体,实体在ID记分板上的分数会被清除,但16384这个 ID 依然存在于 ID 队列中,此时这个 ID 便是无效 ID。
现在执行gc函数(Garbage Collection,垃圾清理的缩写),ID 队列进行了和分配新 ID 时一样的轮转,无效ID16384被推到了队头,被检测为无效 ID,于是被移除 ID 队列,同时其对应的数据空间也被清理。经过一系列操作后再将计算得到的新实体 ID 加到队列末尾:

上面的流程听上去很复杂,但核心思想其实只有一个,就是如何在一个无效 ID 被推到队列首位时将其甄别出来。进一步简化我们的需求,无效 ID 的本质是由于原实体不存在导致了 ID 记分板和 ID 队列的数据不同步,于是问题就变成了如何判断一个 ID 还在记分板上。
由于MC命令的限制,实现像编程语言一样直接遍历整个列表需要的办法都显得很笨,但是MC的记分板依然有一些方便对整个列表进行操作的功能,比如星号(*)能够对所有正在被记分板追踪的目标进行操作,结合operation命令中的比较运算符,我们可以快速地从记分板上找到最大或最小的分数:
# 将所有被追踪目标在A记分板上分数增加100
scoreboard players add * A 100
# 将A记分板上最小的分数赋值给Steve
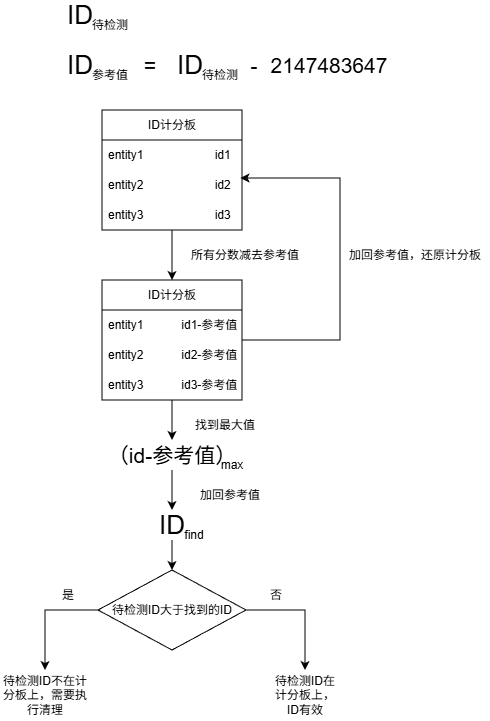
scoreboard players operation Steve A < * A这些简单的功能加上原作者的一些巧思,于是有了下面这套用于判断一个 ID 是否还在记分板上的方法
- 待检测的 ID 减去
2147483647作为参考值 - 对
ID记分板上的所有分数减去参考值 - 获取
ID记分板上最大的分数 - 将所获取的最大分数加回参考值,得到还原的 ID,对
ID记分板上的所有分数进行相同的操作 - 判断待检测的 ID 是否大于还原的 ID,如果是则说明待检测 ID 为无效 ID
2147483647是记分板分数的整数上限,根据整型溢出的规则数值超过这个上限时就会变为负数:
现在假设记分板有我们所要检测的 ID,那么对整个记分板进行操作的过程中这个分数会产生下面的变化:
由于没有任何分数能大于2147483647,所以这时只要获取到的记分板最大分数等于2147483647即可认为要检测的 ID 存在于记分板上。这部分函数实现如下
——————gc.mcfunction——————
# 取队列第一位作为校验ID
execute store result score $ OhMyDat run data get storage oh_my_dat: id[0]
# 减去2147483647作为参考值
scoreboard players remove $ OhMyDat 2147483647
scoreboard players set $ OhMyDatID 0
# 记分板上所有计分项减去参考值
scoreboard players operation * OhMyDatID -= $ OhMyDat
# 找到记分板所有计分项的最大值
scoreboard players operation $ OhMyDatID > * OhMyDatID
# 还原记分板
scoreboard players operation * OhMyDatID += $ OhMyDat
scoreboard players operation $ OhMyDat >< $ OhMyDatID
# 取待校验ID和刚才找到的记分板最大值进行比较,如果大于这个最大值,则说明这是一个无效的id,执行清理
execute store result score $ OhMyDatID run data get storage oh_my_dat: id[0]
execute if score $ OhMyDatID > $ OhMyDat run function oh_my_dat:sys/gc_loop相反的,如果获取到的最大值不为2147483647,那么有两种情况,在对记分板进行变换之前的ID可能大于或小于要检测的 ID,分别记为
由于 ID 分配的区间也就是上面公式中
如果待检测 ID 不在记分板上,那么此时找到的记分板最大值对应的就是 ID 数组中比待检测 ID 小一位的 ID,此时可以认定待检测 ID 不在记分板中应该清理,同时 ID 数组中其它大于这个值的 ID 也应该清理(否则所找到的最高值对应的就不是它了)。于是在gc_loop函数部分,除了清理无效 id 及其对应的数据空间,还会递归对队列的下一位执行相同的操作:
——————gc_loop.mcfunction——————
# 清理id对应的数据空间,并移出id队列
function oh_my_dat:sys/provide
data modify storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][-4] set value {}
data remove storage oh_my_dat: id[0]
# 递归查找队列的下一位
execute store result score $ OhMyDatID run data get storage oh_my_dat: id[0]
execute if score $ OhMyDatID > $ OhMyDat run function oh_my_dat:sys/gc_loop根据id获取数据空间
多维数组的介绍
前面提到,负责对所有实体数据空间进行管理的是命令存储中的一个八维数组。
首先介绍一下多维数组的概念。举一个最简单的数组例子来说,arr数组为[100, 101, 102, 103],索引号0到3分别对应一个数组中的元素,arr[0]对应的数据为100。
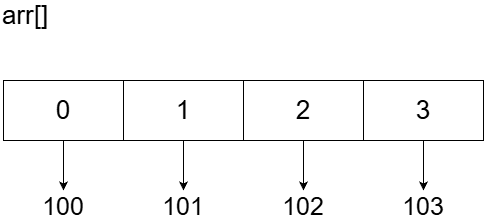
而将数组变成多维的之后,每一层数组的索引号所对应的都会是一个新的数组,而数据变成存于最末端数组中。以二维数组为例,二维数组arr的定义格式为[[100, 101, 102, 103],[],[],[104, 105, 106, 107]]。或许按下面树形书写的方式会更直观一点:
[
[100, 101, 102, 103],
[],
[],
[104, 105, 106, 107]
]在这个二维数组中,arr[0]和arr[3]是有四个元素的数组,arr[1]和arr[2]是两个空数组,如果我要获取到100这个数据,则其索引号为arr[0][0],107则为arr[3][3]
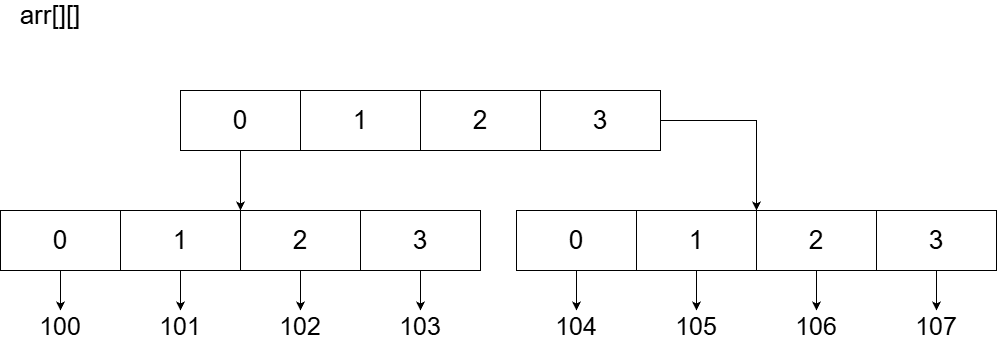
上面数组的例子中插入了空数组,多维数组的每一层元素数量是不同的,此时的多维数组为非矩形数组,而 OhMyDat 用到的八维数组为一个矩形数组,这意味着数组的每一层都有相同数量的元素。对于一个矩形数组来说,其最大存储数据数量为每层元素数量和数组维数的平方。
在上面为实体分配 ID 的介绍中,我们已经知道了实体分配到的 ID 的上限为
将 ID 转换为数组索引
在明白了多维数组是如何工作以及 ID 和多维数组的对应关系之后,接下的任务就是如何根据实体 ID 在这个八维数组中找到对应的数据空间,为了避免混乱,下面先稍微习惯一下八维数组的书写方式
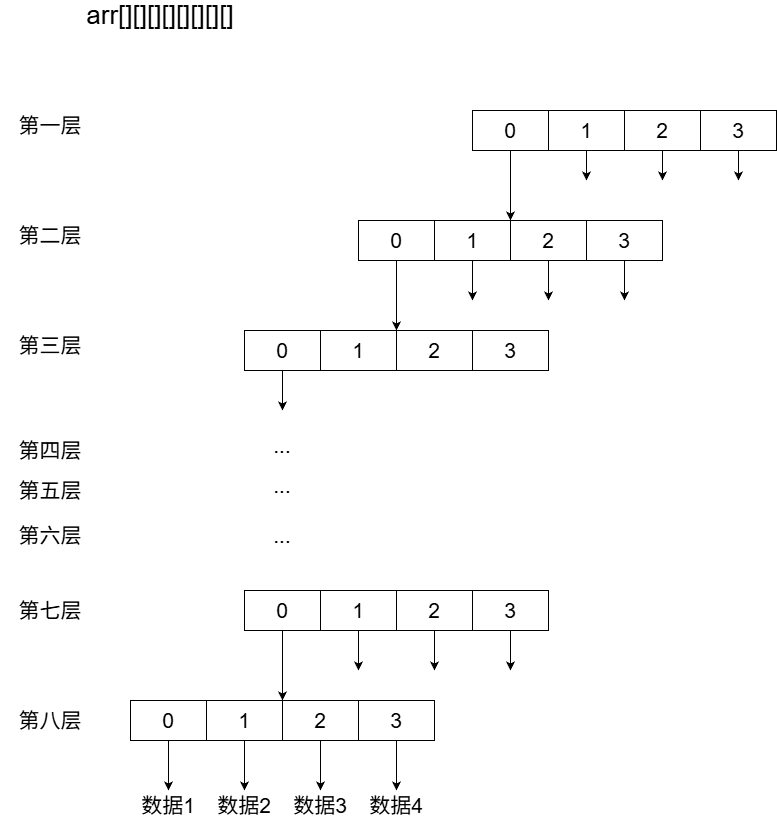
在查找地址的程序运行时,实体的十进制 ID 会先被转换为四进制 ID,以刚进游戏时分配的第一个 id327689为例,其对应四进制数为2000,0000,则对应的在八维数组中的地址如下所示,类似的逻辑,实体 ID 最大值为65535,则其在八维数组中的地址为arr[3][3][3][3][3][3][3][3]。
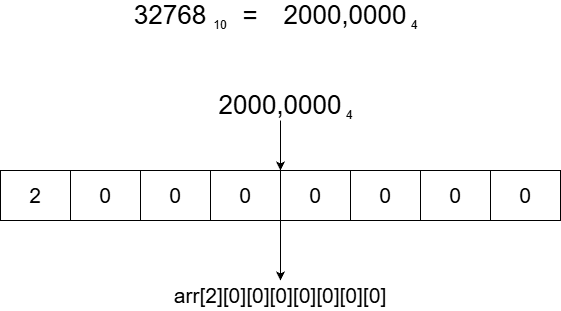
上面的介绍很形象,但通过MC指令实现并没有办法像图示这么直接,实际数位分解流程如下:
- 将 ID 值乘以
65536(),得到第一层偏移量 - 将结果乘以
,得到第二层偏移量 - 将结果乘以
,得到第三层偏移量 - ……
- 将结果乘以
,得到第八层偏移量
Minecraft记分板分数的取值范围为-2147483648 ~ 2147483647(65536(ID值乘以基准值后可以将数值放大到整个取值范围中,同时取值范围可以划分为四个核心区间,每个区间对应四进制数的一个数位偏移量(即四进制数对应数位的值,同时也是八维数组中对应维数的索引值)

每次对ID执行乘以四,本质是将ID的四进制数左移一位,即使运算结果超出ID所属的区间,可确定当前数位的偏移量大小,进而将偏移量映射为八维数组中对应层级的索引。这个方法在前一篇处理经验条时也使用过:
以ID为9999为例,已知其十进制转四进制数为2130033。数位分解运行流程如下:
,处于 ~ 区间,对应偏移量 0,处于 ~ 区间,对应偏移量为 2,处于 ~ 区间,对应偏移量 1,处于 ~ 区间,对应偏移量 3- (其它数位以此类推)
根据索引获取数据空间
通过上面数位分解的流程我们已经得到了实体 ID 经过转换后的在八维数组中的索引号,将索引号传入数组即可得到我们想要获取的实体数据空间,但MC指令中除非使用宏否则并没有提供直接传入索引到数组的方法,于是有了下面这种通过负数索引定位元素的方式:
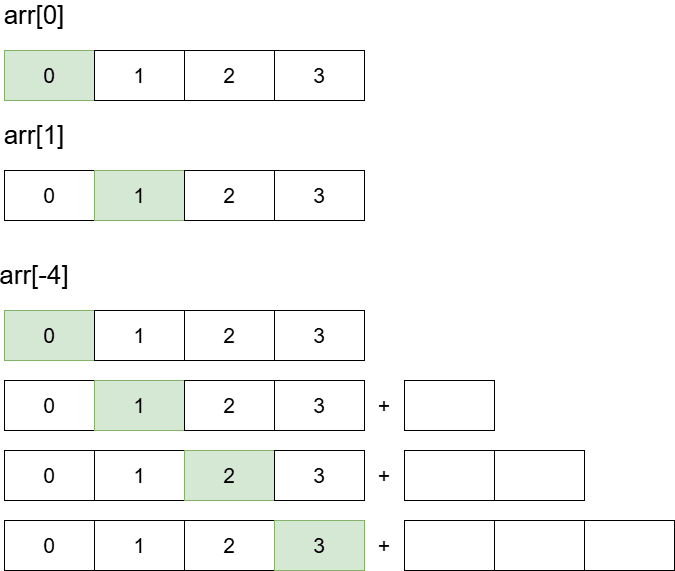
arr[-4]表示数组从后往前数的第四个元素,在不改变原数组数据的情况下,可以在数组末尾添加空元素,根据所需要获取的索引号添加指定数量的空元素,这样arr[-4]就可以精准指向我们所要定位的元素。
依然以ID为9999的实体为例,前面我们已经知道了其四进制为2130033,则对应的数组索引为arr[0][2][1][3][0][0][3][3](注意补齐到
- 第一位为
0,则不追加空元素,第一层arr[-4]指向arr[0] - 第一位为
2,则向arr[-4]这个数组追加两个空元素,第二层arr[-4][-4]指向原来的arr[0][2] - 第一位为
1,则向arr[-4][-4]这个数组追加一个空元素,第二层arr[-4][-4][-4]指向原来的arr[0][2][1] - 第一位为
3,则向arr[-4][-4][-4]这个数组追加三个空元素,第二层arr[-4][-4][-4][-4]指向原来的arr[0][2][1][3] - (其它数位以此类推)
需要注意的是,由于添加空元素是在整个八维数组中进行的,所以如果切换了要获取数据空间的对象,每次都要先对先前追加的空元素进行清理,于是在provide函数的开头能看到这么长的一段,其作用就是在不改变每层数组前四位的情况下清理后三位的空元素
——————provide.mcfunction——————
# 清理空元素
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][6]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][5]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][4]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][6]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][5]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][4]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][6]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][5]
data remove storage oh_my_dat: _[-4][-4][-4][-4][-4][4]
data remove storage oh_my_dat: _[-4][-4][-4][-4][6]
data remove storage oh_my_dat: _[-4][-4][-4][-4][5]
data remove storage oh_my_dat: _[-4][-4][-4][-4][4]
data remove storage oh_my_dat: _[-4][-4][-4][6]
data remove storage oh_my_dat: _[-4][-4][-4][5]
data remove storage oh_my_dat: _[-4][-4][-4][4]
data remove storage oh_my_dat: _[-4][-4][6]
data remove storage oh_my_dat: _[-4][-4][5]
data remove storage oh_my_dat: _[-4][-4][4]
data remove storage oh_my_dat: _[-4][6]
data remove storage oh_my_dat: _[-4][5]
data remove storage oh_my_dat: _[-4][4]
data remove storage oh_my_dat: _[6]
data remove storage oh_my_dat: _[5]
data remove storage oh_my_dat: _[4]其它部分就如解析的一样逐层进行共八次,多了一步复制 initial(一个初始化时定义的空八维数组)的结构防止找不到对应索引的元素
——————provide.mcfunction——————
# 第一层
scoreboard players operation $ OhMyDatID *= $65536 OhMyDatConst
execute if score $ OhMyDatID matches 1073741824.. run data modify storage oh_my_dat: _ append value []
execute if score $ OhMyDatID matches ..-1073741825 run data modify storage oh_my_dat: _ append from storage oh_my_dat: two_empty_lists[]
execute if score $ OhMyDatID matches -1073741824..-1 run data modify storage oh_my_dat: _ append from storage oh_my_dat: three_empty_lists[]
# 第二层
execute unless data storage oh_my_dat: _[-4][0] run data modify storage oh_my_dat: _[-4] set from storage oh_my_dat: initial[0]
scoreboard players operation $ OhMyDatID *= $4 OhMyDatConst
execute if score $ OhMyDatID matches 1073741824.. run data modify storage oh_my_dat: _[-4] append value []
execute if score $ OhMyDatID matches ..-1073741825 run data modify storage oh_my_dat: _[-4] append from storage oh_my_dat: two_empty_lists[]
execute if score $ OhMyDatID matches -1073741824..-1 run data modify storage oh_my_dat: _[-4] append from storage oh_my_dat: three_empty_lists[]
execute unless data storage oh_my_dat: _[-4][-4][0] run data modify storage oh_my_dat: _[-4][-4] set from storage oh_my_dat: initial[0][0]
# 第三层
scoreboard players operation $ OhMyDatID *= $4 OhMyDatConst
execute if score $ OhMyDatID matches 1073741824.. run data modify storage oh_my_dat: _[-4][-4] append value []
execute if score $ OhMyDatID matches ..-1073741825 run data modify storage oh_my_dat: _[-4][-4] append from storage oh_my_dat: two_empty_lists[]
execute if score $ OhMyDatID matches -1073741824..-1 run data modify storage oh_my_dat: _[-4][-4] append from storage oh_my_dat: three_empty_lists[]
execute unless data storage oh_my_dat: _[-4][-4][-4][0] run data modify storage oh_my_dat: _[-4][-4][-4] set from storage oh_my_dat: initial[0][0][0]
# 以此类推……经过上面的步骤最终arr[-4][-4][-4][-4][-4][-4][-4][-4]的地址即为实体 ID 所对应数据空间的地址,上面一系列步骤经过封装,于是最终使用时就会变成最开始演示的样子
function oh_my_dat:please
data modify storage oh_my_dat: _[-4][-4][-4][-4][-4][-4][-4][-4].Data set from entity @s未解之谜
一边debug一边撰稿也吃了不少次AI幻觉的亏,逆推算法确实是个很大工程,所以原地图团队的技术思路真的太狠了。上面总结好思路的内容已经足以进行复刻了,但在gc函数中还有一段遗留的内容用于控制函数是否递归,一直看不出思路尤其是还用到了一条计算公式,如果有能理解这套算法的读者还望联系我修改
execute store result score $ OhMyDat run data get storage oh_my_dat: id[-1]
execute if score $ OhMyDat matches 0 run scoreboard players add $ OhMyDat 65536
execute if score $ OhMyDatID matches 0 run scoreboard players add $ OhMyDat 65536
execute if score $ OhMyDatID matches 0 run scoreboard players add $ OhMyDatID 65536
scoreboard players operation $ OhMyDat += $ OhMyDat
scoreboard players operation $ OhMyDat -= $ OhMyDatID
scoreboard players operation $ OhMyDat -= $ OhMyDatID
scoreboard players operation $ OhMyDatID -= $ OhMyDat
execute store result score $ OhMyDat run data get storage oh_my_dat: id[1]
scoreboard players operation $ OhMyDatID -= $ OhMyDat
execute if score $ OhMyDatID matches -1.. run function oh_my_dat:sys/gc
附录
TheSkyBlessing 地图项目仓库
GitHub - ProjectTSB/TheSkyBlessing: TheSkyBlessing のベース Datapack のリポジトリ
OhMyDat 轮子数据包仓库
GitHub - Ai-Akaishi/OhMyDat: Minecraft Private Storage Datapack